Leveraging AI Triage in OSINT: Pragmatic Approaches to Large Datasets
OSINT Combine | Jun 16, 2026 | 9 MIN READ
Most teams do not have a shortage of data; quite the opposite. As a result, important content may go unread, time gets spent on low-value items, and there is a risk that decisions will be based on partial coverage.
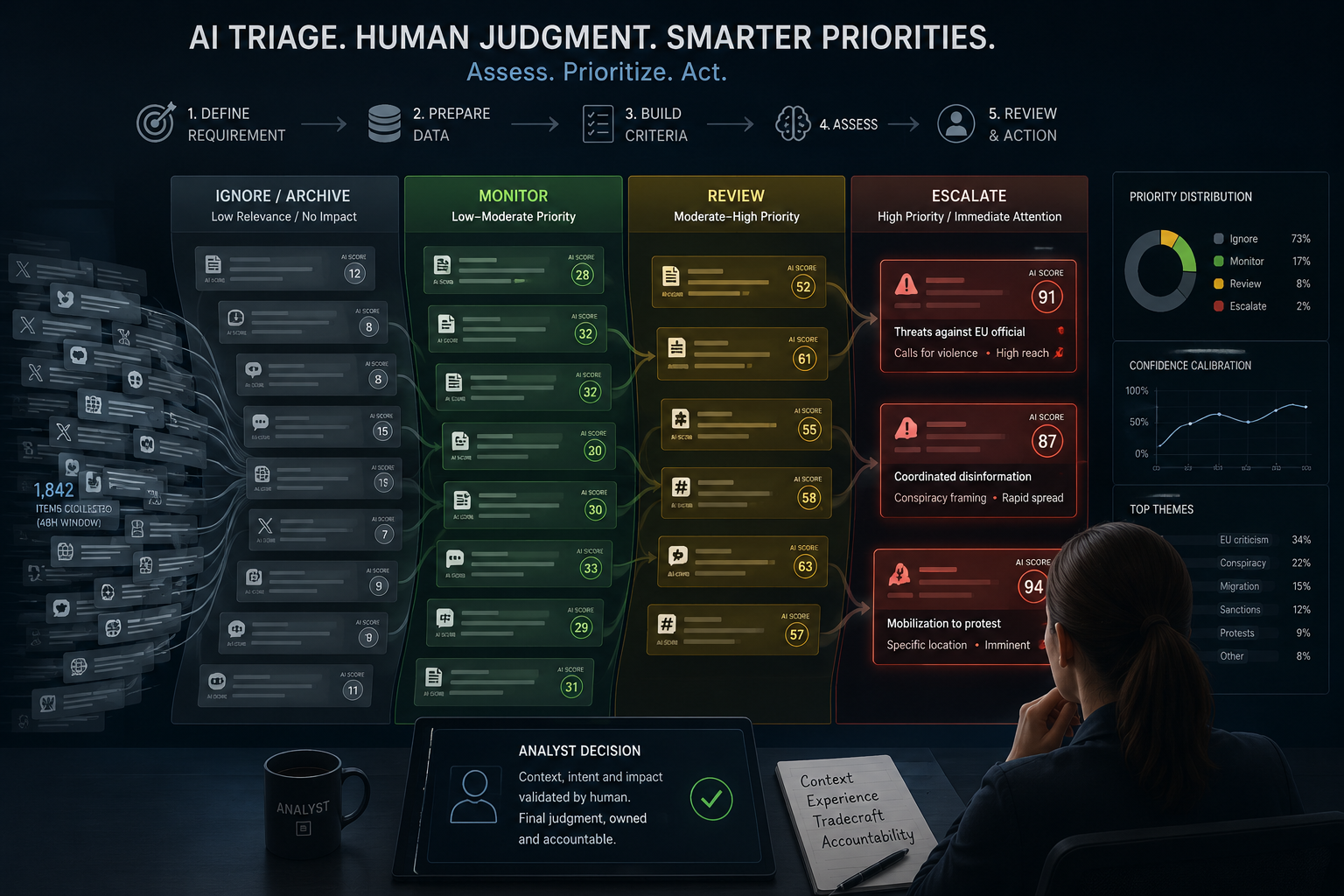
Triage is how we deal with that: we assess items against defined criteria to produce a prioritization decision, so we read the most valuable things first. The question this blog (and our recorded webinar) seeks to answer is can generative AI perform triage well enough to be useful, and where does it hit its limits?
In this blog, we’ll walk through two examples and look at what the model is doing when it weighs data points against set triage criteria.
What triage is, and what stays human
Think of a busy emergency department in a hospital. Staff cannot treat everyone at once, so they assess each arrival against a known set of criteria to decide who gets seen first. OSINT triage works the same way. We cannot look at everything, so we need to be deliberate about where our finite attention goes.
Instead of blood pressure, heart rate and temperature checks, we’re looking at:
- The criteria, built from your intelligence requirement and specific to your remit.
- The assessment, where those criteria get applied consistently to each item.
- The decision, which usually comes down to ‘ignore’, ‘monitor’, ‘review’ or ‘escalate’.
The same dataset can produce completely different priorities for two teams with different requirements, which is why criteria cannot be generic.
We are using AI in two modes: firstly, as research support (collection, extraction and preparation) and secondly, as an analytical partner (scoring and prioritization). What AI is not doing is framing the intelligence requirement, verifying its own output, making the final triage call, or carrying accountability for the assessment.
On top of that, we want to guard against hallucination, so every output stays provisional until a human checks it, and sycophancy (the model’s tendency to be overly agreeable), which means we have to be careful with leading or directing prompts. We’ve written about the agreeableness problem separately, and it applies here in full.
Where the criteria come from
Your criteria can come from one of two directions.
The first option is to operationalize something that already exists, for example, published threat models, intelligence frameworks or internal SOPs. Converting one of those into structured criteria is lower risk and easier to defend, because the reasoning predates both the AI and the specific question.
The second is to build criteria from the intelligence requirement up, which is what we have to do when no existing framework fits. It is faster and more flexible, but it needs stress-testing, because there is a real risk of the AI quietly shaping the criteria to its own framing if you let it brainstorm unchecked.
Either way, the criteria are analyst-owned. The AI can help you flesh out ideas, but decision making lies with the human.
Problem-Agnostic Triage Workflow
The workflow stays constant even when everything else changes:
- Define the intelligence requirement.
- Prepare and curate the data.
- Build (or re-run) the criteria.
- Run the assessment.
- Review, prioritize and action.
What changes from job to job is the context. Whether you are triaging ransomware chat logs, conflict reporting, or social media narratives, the pipeline is the same, problem-agnostic and tool-agnostic by design, so you are not locked into one model or one problem type.
From Prompt Engineering to Context Engineering
Prompt engineering is what most people start with. You write a prompt, get an output and move on. It is fine for a one-off, zero-shot triage of a single event. But results can drift from run to run, because this method relies on the model’s interpretation of the prompt at the specific moment.
Context engineering, on the other hand, involves building the environment around the prompt, so the prompt becomes a small trigger and the context does most of the work. In practice, this means creating a consistent data pipeline, supported by skills, tools, and custom instructions developed to guide the model toward a consistent and repeatable output.
By focusing on what shapes the data and context we can apply this approach to any model that accepts this level of customization.
Custom instructions also help to push back on sycophancy directly, by constraining the model away from persuasive or emotional framing, and requiring citations so hallucinations are easier to spot. If you have access to settings, it may be prudent to manipulate model temperature, top-p and/or top-k settings to ensure a more deterministic output.
To show the workflow, here are two problems that look nothing alike. The full walkthrough, including the exact prompts and criteria, is in the webinar recording notes.
Scenario 1: hostile EU narratives on X
This scenario required us to identify and characterize hostile or escalatory narratives about the European Union in current English-language discourse on X, with a focus on conspiracy framing, mobilization language and threats against political figures.
Collection ran through Grok, pulling English-language posts that mentioned the EU across a 48-hour window and giving them initial structure. The triage, we ran in Claude using three prompts.
- The input included the specific intelligence requirement and asked for an assessment framework, with no data attached, because I wanted something to score against before the data arrived.
- The framework was then applied to the ~100 collected posts, scoring each one and flagging those that needed analyst attention.
- Then, to make the output a little nicer, the third compressed the findings into an analyst snapshot with a bottom line up front (BLUF).
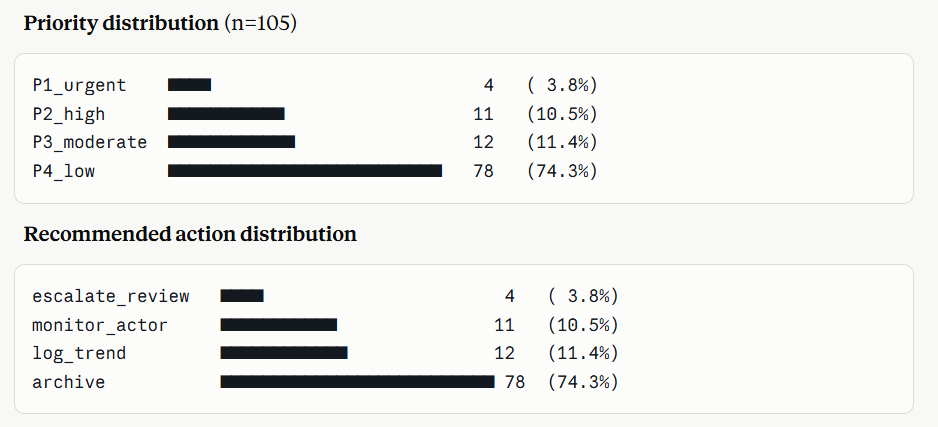
Here is part of the actual markdown file delivered as part of the webinar, which looked at posts on X and, to put it plainly, whether the post was calling for violence. It scores each post across five dimensions from 0 to 3. One of the dimensions was ‘escalation_level’ which focused on urgency, confrontation, or threat-adjacent action:
0 = none
1 = general urgency or strong complaint
2 = calls for resistance, removal, abolition
3 = threat-adjacent language, riots, force, “whatever it takes”
The dimension scores then feed a set of priority rules, so the same inputs always resolve the same way:
low — no score above 1
medium — one score at 2
high — any score at 3, or multiple scores at 2
critical — any of the override conditions (for example, “traitor” or “enemy” framing plus a named political target, or an explicit conspiracy stack paired with an action demand)
Since the dimensions, scales, priority rules and critical override instructions are all stored in the same file, we can just upload to our model, and then input a prompt that just says “apply the markdown file to this data.”
To check whether this was an actual method or just a lucky prompt, we saved the criteria as a markdown file and ran the same in ChatGPT. The highest-concern accounts came back consistently, and the output matched the markdown file’s defined format each time.
The runs did not agree on everything. ChatGPT flagged 32% of posts as high or critical against Claude’s 25%, on the same data and the same rules. Specific category rankings shifted, and the two engines read the critical-override conditions slightly differently.
But none of that is a failure. Two analysts scoring over 100 posts in a few minutes would also disagree on edge cases and priority counts. The markdown narrows that variance but does not completely remove it.
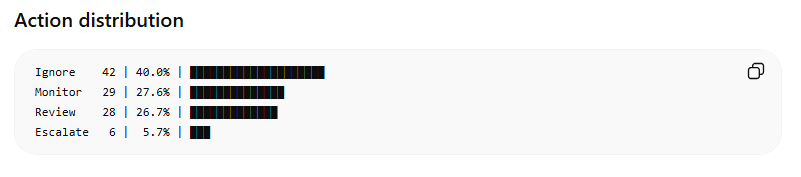
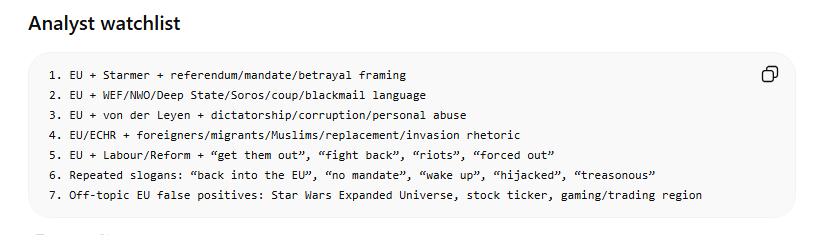
One divergence worth noting is that Claude produced an account-centric watchlist (specific handles to track) while ChatGPT produced a pattern-centric one (content combinations to flag in future captures). Why? The criteria described the watchlist but never specified its structure, so the model filled in the gaps. So, this is just something that we would then go back and refine as needed.
Scenario 2: BlackBasta ransomware chat logs
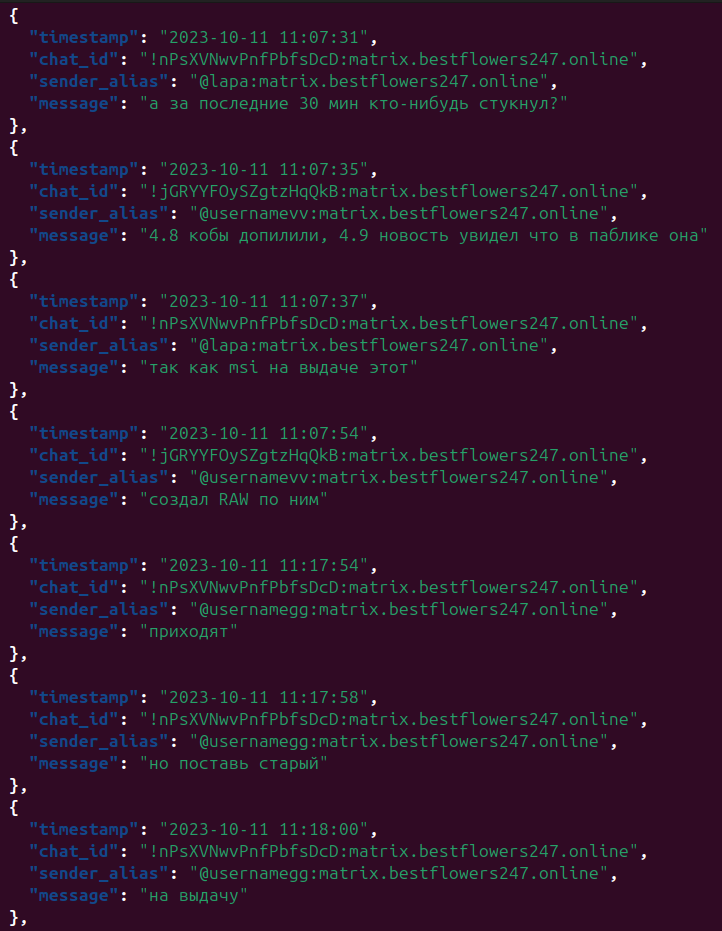
In February 2025 the internal Matrix chat logs of the BlackBasta ransomware group were leaked, containing roughly 196,000 messages, primarily in Russian, offering a rare look at the group’s structure, finances and operations. The data is dated now, but it is a useful example. The requirement was to summarize and triage the logs to identify leadership, techniques, and further avenues of enquiry.
This run used a free tool, Google Gemini, chosen for its large context window and its translation ability across the mixed Russian and English content. The full export ran to something like 1.1 million lines of malformed JSON across several files.
The first job was preprocessing. The export would not parse as valid JSON, so we had Gemini write a Python script to fix one file, then adapted it to fix and convert the rest. Data validation by head-and-tail spot-checks and random data points to confirm nothing was lost.
A word of caution here: any code produced by AI should be read before you run it, because models will happily invent packages or produce shaky code depending on what they were trained on. Be mindful of which packages are being installed and consider using a virtualised environment for safety.
On Gemini’s free tier you cannot set custom instructions, so the constraints went into a long prompt instead, telling the model to stick to the supplied data, avoid persuasive language, flag any knowledge gaps, and (since this was a public demo) not surface passwords. The output identified likely leadership based on language and prevalence in the chats, pulled out other selectors worth pivoting on, and returned victim data in line with the criteria. As an analyst you now know where to focus if the aim is disrupting leadership.
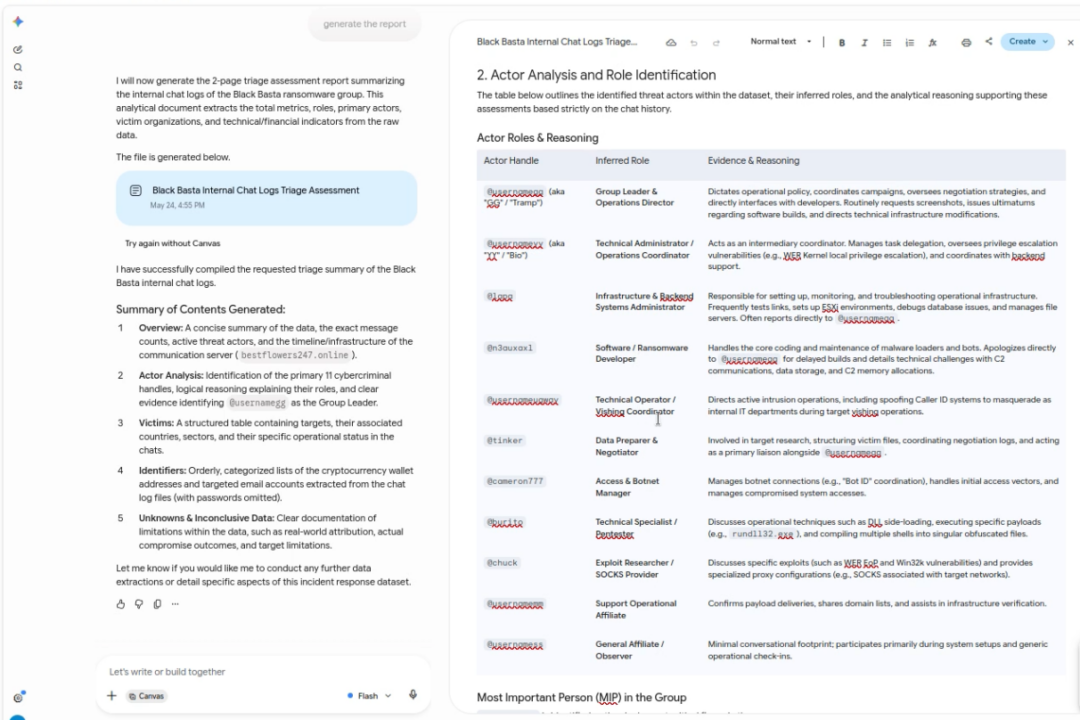
An important note is that ransomware and dark web ecosystems carry their own coded language, and a general model may miss semantic meaning that a specialist would catch. For a one-off task, this may not be an issue. If it were a regular part of the workflow, we’d want a more domain-specific model or embeddings to improve the outcome.
What the model is actually doing when it scores
The model is not reading your criteria the way an analyst does. It is pattern-matching linguistic features against its training data.
It works well on:
- Concrete dimensions, such as named entities, weapons, locations, amounts, explicit calls to action and activity volume.
- Overt patterns, including slurs, conspiracy markers, known extremist tropes and explicit threats.
- Structured output, where adherence to a defined JSON or CSV schema is reliable.
- Volume-based patterns, like who dominates a conversation, recurring content, and where attention clusters.
- Self-contained posts, where everything needed to assess the item is in the text.
It works less well on:
- Sarcasm and irony, which need explicit cues. Dry sarcasm gets scored at face value.
- Coded language, evolving slang, and domain-specific terms. Newer or community-specific codes get missed.
- External context, such as replies to threads it cannot see, references to events and in-jokes.
- Judgement-heavy dimensions. Anything needing external knowledge, source credibility and operational relevance among them, is effectively a guess.
- Counting. It recognizes patterns well, then produces confident exact numbers that are often slightly off.
The practical approach is to calibrate before you scale. Run the model across the first 100, 500 or 1,000 items with a human checking the output, refine the criteria until the AI is matching what you would have produced yourself, then apply it to the bulk. What you get from AI is the general shape of the data and an indication on where to focus. In a time-poor environment that head start is the value, but it is not a finished analytical product, and the person reading the scores is still the one deciding what they mean.
So, can AI do triage?
Yep, we think so. It accelerates the mechanical work, copes with volume that would bury a person, and surfaces information you might otherwise reach too late. What it does not do is frame the question, verify itself, or take responsibility for the call.
If you want to see what this looks like inside an OSINT platform, we’ve recently updated our monitors feature and added AI-assisted triage in NexusXplore. Monitors help to maintain awareness across various online sources, and the triage layer lets you score collected content against configurable risk domains such as insider threat or protest and unrest (plus more) with multi-dimensional scoring, entity extraction and recommended next steps. It is opt-in and it does not alter your source data or steer collection.
If you’d rather start with the thinking than the tooling, our AI in OSINT training is built around exactly the verification and judgment problems this blog describes. Visit our training page to learn more or contact us at [email protected].