What AI Can’t Be Trained On: Human Judgement in OSINT
Jacob Hunter | Apr 18, 2026 | 11 MIN READ
Generative AI is increasingly embedded in OSINT workflows. But the question of where human judgement remains essential, and why, is worth examining closely. Phoebe Yao, founder and CEO of an AI training data company, recently argued that “90% of human expertise is not verifiable.” That framing stuck with me, and this blog is the result.
AI can only be effectively trained on tasks where you can clearly tell whether the answer is right or wrong. A chess move leads to a win or a loss. Code runs or it doesn’t. But most of what experts actually do doesn’t have a clean correct answer you can check. And for AI training, no checkable answer means no reliable learning.
This brings me to a 2023 paper: We’ll never have a model of an AI major-general by Hunter and Bowen, published in the Journal of Strategic Studies. The argument is that AI cannot make or advise on military command decisions, not because the technology isn’t there yet, but because war requires a type of reasoning AI structurally doesn’t do.
The training problem, briefly
Modern AI is generally refined through feedback loops. Produce good output, get rewarded. Produce bad output, get penalised. This works well when “good” and “bad” are unambiguous. It works terribly when they’re not.
The workaround is to over-specify tasks until they become gradeable. Make it simple enough to score. The problem is that this strips out exactly the parts where expert judgement matters. You end up training confident instruction-following, not expert reasoning. The output looks right. That’s not the same as being right.
Hunter and Bowen call the military version of this a “kitsch” vision of war. To argue AI can make command decisions, you have to quietly redefine command decisions as something calculable, something with a correct answer. Once you do that, you’ve stopped talking about command decisions. You’ve started talking about something tidier that you’ve decided to call command decisions. The AI beats a human in a simulated one-on-one dogfight and everyone gets excited. But the scenario removed almost everything that makes tactical command hard. The AI didn’t decide whether to engage, it just flew the plane. The scenario also has a set of rules. Real operations don’t work that way as humans are unpredictable plus the terrain and weather shift.
A more OSINT-grounded example is entity extraction from a load of documents. AI doesn’t know what the connections actually mean, or how the context changes the overall intelligence picture. It can’t tell me who is significant or what matters in relation to everything else I know on this target. It will respond if you ask, but there are problems with this, as we’ll discuss further.
Induction vs. abduction (stay with me, it’s interesting I promise)
Hunter and Bowen draw a distinction that doesn’t come up much in mainstream AI commentary.
Inductive logic: draw conclusions from patterns in observed data. This is what machine learning does. Find the pattern, extrapolate. At its core, every large language model and classifier is induction at scale.
Abductive logic: reach the conclusion that best explains a situation, especially when the data is incomplete, and especially when the explanation requires going beyond what the data directly shows. It’s the detective who doesn’t have proof but makes the inference that accounts for all the available facts. It’s the analyst who recognises that the absence of expected activity is in itself significant.
The argument is that command decisions require abductive reasoning to make sound and safe decisions in the face of the unknown. An AI is limited to inductive reasoning by virtue of its training. More data and more compute don’t bridge that gap because the gap is logical, not quantitative.
Worth noting here, Hunter and Bowen wrote this in 2023. Frontier LLMs are a different proposition. Are they genuinely reasoning abductively or just doing very convincing induction? The honest answer is that nobody has settled this yet. The benchmarks that exist test for pattern-matching at scale, not for the kind of inferential leaps abduction requires. There’s also a real possibility that frontier models will eventually do something functionally indistinguishable from abductive reasoning. History suggests that declaring any cognitive task permanently beyond AI is probably a losing bet. And even if frontier models are starting to blur the line, the verification problem doesn’t go away. You still can’t confirm whether the abductive leap was sound.
And, well, that just brings us back to where we started.
From an OSINT perspective, this maps cleanly. The mechanical tasks, geolocation, translation, entity extraction, chronolocation, pattern matching across datasets, are inductive. Apply method to data, check result. AI is good at these and genuinely speeds them up.
The analytical tasks like assessing source reliability when indicators conflict, recognising inauthentic content, inferring intent from incomplete behavioural data, or identifying what’s missing from a picture, are all abductive. There’s no historical pattern to draw conclusions from. The situation is new, the ground truth is moving fast, and the right answer often can’t be verified even after the fact. That’s the 90% Yao is talking about.
Let’s look at an example, as the same logic applies to detecting influence operations. A coordinated surge of social media accounts pushing a domestic narrative around an election isn’t easily identifiable as foreign interference. An analyst would have to look at the context, patterns, timing, target audience, platform choice, message, and agenda to identify the true foreign hand behind the interference. After processing, evaluation, analysis, integration, and interpretation of disparate pieces of information, we have the makings of intelligence. Taiwan’s 2024 election is one of the most documented examples of exactly this kind of cognitive warfare, and countering it is an analytical problem.
Reproducibility isn’t the same as verifiability
Reproducibility means another analyst can follow your reasoning. Verifiability in the AI training sense means there’s a deterministic correct answer you can check. You can have a perfectly reproducible process that still produces a judgement no one can verify as right or wrong.
An analyst assessing whether a country will take a significant action in the next six months can document everything. But whether the assessment is correct may not be knowable for months. And even then, did the action not happen because the assessment was wrong, or because the assessment led to deterrence? The feedback loop that AI training requires often simply doesn’t exist.
Techniques like Analysis of Competing Hypotheses, key assumptions checks, and confidence levels exist because outcomes are so often unverifiable. A good analyst gives the decision-maker the clearest possible picture and doesn’t hedge their bets. None of this goes away because you’ve added AI to the process.
None of this means human judgement is reliable by default. Analysts anchor on early information, fall into groupthink, see patterns that aren’t there. The argument here isn’t that humans are good at this and AI isn’t. The failure modes are just different as human ones are at least partially correctable through training, tradecraft, experience and peer review. AI mistakes are harder to spot because they arrive looking polished and sounding certain.
The jagged frontier
Ethan Mollick’s “jagged frontier” framing is useful here. Models are superhuman at some tasks, surprisingly weak at others, and the distribution doesn’t map onto what you’d expect. AI can outperform specialists at certain diagnostic tasks but fail at something super simple e.g., “@grok is this true?”. It can write sophisticated code but confidently fabricate citations.
The Anthropic research on labour market impacts illustrates a related point: the gap between theoretical AI capability and what’s actually observed in practice varies wildly across occupational categories. That unevenness is the jagged frontier.
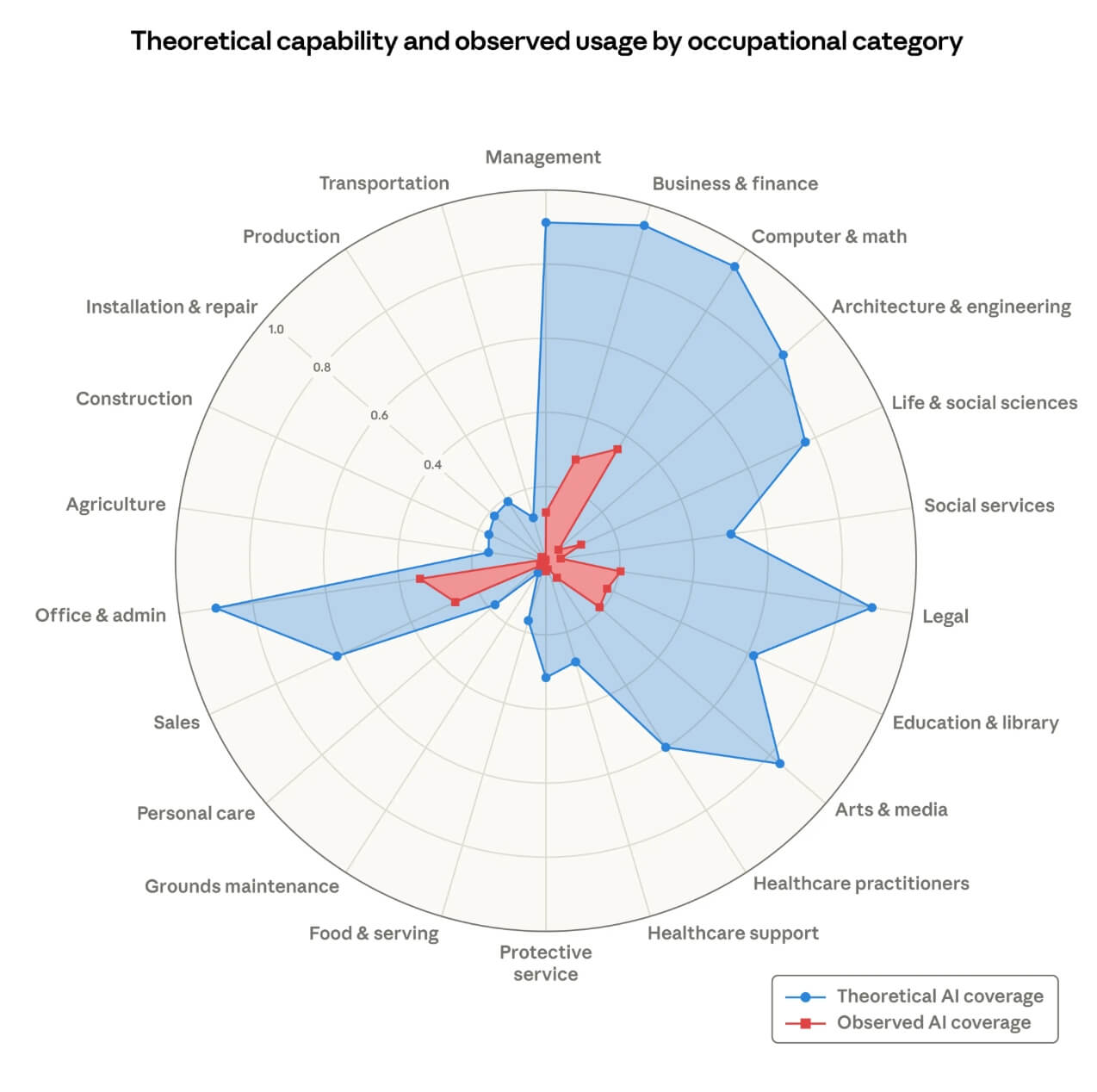
Because the frontier is jagged rather than smooth, you can’t just assume AI is reliable on anything that feels like the kind of task it should be good at. The fastest calibration tool is to use it on something you know well, really well, then push back hard on the output. You’ll find out pretty quickly where the frontier is. And that gap between how certain it sounds and how certain it actually is, is the verification problem.
I use generative AI most days, but there is a risk in assuming the output is always trustworthy, despite how polished the answer is.
The sycophancy problem is the same problem
That gap between confidence and correctness isn’t just an accident of the frontier. Models optimised for user satisfaction produce agreeable, confident responses even when the right response is uncertainty or pushback. The model doesn’t know it’s on the wrong side of the frontier. It just sounds like it’s on the right side, every time.
For intelligence work, something along the lines of “the evidence is contradictory” may be significant in itself. However, a model trained to maximise user satisfaction will over-produce authoritative-sounding outputs. If you’ve spent any time working with AI outputs on ambiguous questions, you’ve probably noticed.
We’ve written about this more here. Confidence and correctness are not the same thing and generative AI is often trained to optimise confidence.
Knowing where to start
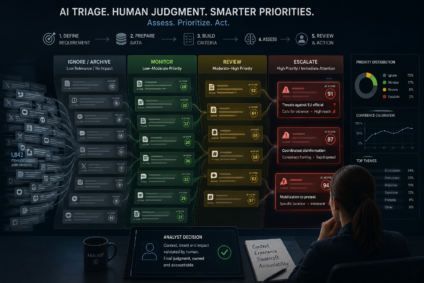
Most of the AI-in-OSINT conversation focuses on four usage modes: planning, research, analysis, and communication. That tracks with the intelligence cycle, which makes sense. But there are two aspects of the cycle that rely heavily on human judgement, potentially more so in the age of AI, and they rarely come up.
The first is knowing when to start. This sits within the planning phase of the intelligence cycle: working out which questions, asked in which order, will actually resolve the intelligence requirement. What to prioritise, and where to focus limited collection effort. These are judgement calls that draw on everything you’ve seen before: what’s gone wrong in the past, what decision-makers actually need versus what they say they need, what’s changed in the operational picture since last week and what legislative or policy constraints apply, including what proportionate action looks like in context. Some of this lives in the analyst’s head, built up through years of doing the work. But much of it flows from formal requirements such as National Intelligence Priorities, Board Priorities or simply organisational tasking. The analyst should interpret those, and make judgement calls accordingly. AI, in this respect, cannot replicate that judgement. Some of it might be documented (and AI could use this as context) but what was written down will be lopsided and stripped of the nuance.
There’s also a temptation here: when AI can help draft a collection plan in seconds, the pull to skip past the hard thinking about what actually needs collecting gets stronger (because we want to get to the fun collection part!). In this, speed is the risk. Worth pausing to ask what the plan is actually for. If it exists to tick a compliance box rather than to shape things like considered risk management, prioritisation, and proportionate action, the speed AI offers just gets you to a worse plan, sooner.
Knowing when to stop
The second is knowing when to stop. There’s always more to collect, always another thread to pull. The decision to say “this is good enough” is a judgement about the consumer, the tempo, the cost of waiting, and whether continued collection remains proportionate and defensible from a privacy standpoint. Get it wrong and the product either arrives too late to matter or goes out half-baked.
This again is from lived experience and good training (of the human).
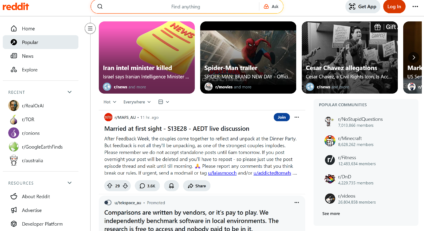
This problem plays out at the micro level too. The screenshot below shows an AI chatbot that doesn’t know when the conversation is done, prompting follow-up questions and keeping the exchange going rather than letting it end naturally. Sometimes referred to as “multi-turn engagement”: the model has no sense of when enough is enough.

Both of these sit firmly in Yao’s 90%. And they’re worth calling out because they’re the stages where an over-reliance on AI is most likely to go unnoticed. If AI helps you process data faster during analysis, great. But if a completely AI-produced report lands on the boss’s desk, unverified and not critically reviewed, and poor decisions follow, not so great.
What this means practically
The verification problem is structural, not temporary. So:
Use AI for verifiable tasks: keyword expansion, entity extraction, translation, summarisation, geolocation support, or large-volume data processing. These are the mechanical tasks where AI performs and where outputs can be checked.
Apply structured analytic techniques as human methods applied by humans: ACH, key assumptions checks, or devil’s advocacy. AI can be useful here in a limited way, the back-and-forth of stress-testing an assessment, poking at assumptions, surfacing angles you hadn’t considered. Think of it as replicating the contestability conversation with a colleague. But that’s very different from the hard brain labour of actually building the analysis. It can’t do the thinking that makes that conversation worth having.
There’s emerging evidence this distinction matters more than it might seem. A 2025 preprint from MIT’s Media Lab ran EEG scans on people doing writing tasks across three groups: AI-assisted, search engine, and no tools. Neural connectivity scaled down directly with the level of external support, with the AI group showing the weakest engagement. 83% of AI-assisted participants couldn’t recall a sentence from their own writing 60 seconds after finishing, and most reported little ownership over what they’d produced. It’s a small sample in an educational context, so treat it as suggestive rather than definitive, but the researchers’ framing is apt: “cognitive debt.” This is costly because thinking is the whole point.
Verify every claim. Trace back to primary sources. The AI suggested it, you still have to assess it. Document your reasoning, especially where AI contributed. The failure modes are less visible with AI in the chain. An AI that produces a confident but wrong summary looks exactly the same as one that’s right.
Our frameworks for citing AI, evaluating outputs, and managing integration aren’t an attempt to fix the problem, rather for the development of process and mindset that accounts for working with AI.
The bottom line
AI can be genuinely useful. It accelerates the mechanical parts of the work, handles volume, and surfaces leads you might have missed.
But the 90% of analytical work that depends on human judgement isn’t going away. The structural reasons for that, the ones Hunter and Bowen identified from military theory and Yao identified from AI training methodology, suggest this isn’t just a matter of waiting for the next model release. For intelligence analysis and OSINT, where the right answer is often unknowable and the cost of false confidence is high, that 90% is the job.
If the 90% is the job, the question is how you protect it. Two things we’d point you to: our AI in OSINT training, which is built around the verification and judgement problems this blog describes, and NexusXplore, our OSINT platform that applies AI selectively and tells you distinctly where it’s been used.