The Transliteration Problem in OSINT
Evan Davies | Oct 14, 2019 | 6 MIN READ
Updated: May 2, 2023
Introduction
Open source investigations routinely require the use of translation tools to assist with language barriers as targets may post or engage online using multiple languages. When using English as a base language, any collection in a foreign language that does not use Western-style Roman lettering will result in the requirement to transliterate the original language so it can be used for processing and analysis.
This is inherently vulnerable to unintentional error and inaccuracy when the information is translated back out to its original form for reporting and evidentiary purposes. This inaccuracy in reporting could lead to failed prosecutions due to collection inaccuracies when pivoting to additional information about an individual. Linguistic details are paramount. Literal accuracy matters.
The Arabic language provides a prime vignette for addressing the procedural issues that corrupt the accuracy of the intelligence cycle when collecting open source information. This paper explores this problem and provides a simple procedural solution to ensure accuracy in producing intelligence from open source information. It is important to have a basic understanding of the intelligence cycle and where collection, processing and analysis lead to intelligence production.
The Transliteration Problem
The requirement to translate non-native languages, such as Arabic to English, creates inherent probability of deviation in the accuracy of the translated information[1]. Details pertaining to the human and physical terrain are vital to ensure accurate and legal investigations based on the direction given. The name of a person must be valid if it is to serve as the basis for investigation and prosecutions just as the accuracy of locations should be when supporting ground-based operations such as surveillance and the inherent reporting that is required post-operation.
Historically the requirement to transliterate from non-English native languages to English and back has been addressed through the introduction of technological tools that use common transliteration to standardises naming references in English. However, these tools only addressed the consistency of the information and do not provide a reference point to validate the information during analysis and when intelligence product is being disseminated out.
For evidentiary purposes and any warrant based operation where the target originates from a non-Western country there will ultimately be a requirement for the name of the individual to be available in the native language, however it is possible that not all individuals conducting the investigation will be able to read and write in the language required.
Failing to properly validate the individuals name in the native language could result in the inadvertent targeting of two completely different individuals. In giving linguistic context to the problem, the English language has roughly 600,000 non-repeated words when using the largest known English dictionary. The Arabic language has over 12,300,000 non-repeated words[2] . Mathematically this creates significant potential error rates when translating between the two languages.
The problem is not a failure of any individual in the intelligence cycle but rather the absence of a validation processes surrounding the collection of information through to its dissemination as intelligence.
Inputs & Outputs
The following diagram depicts a common interaction with a partner force element and its association with the intelligence cycle:
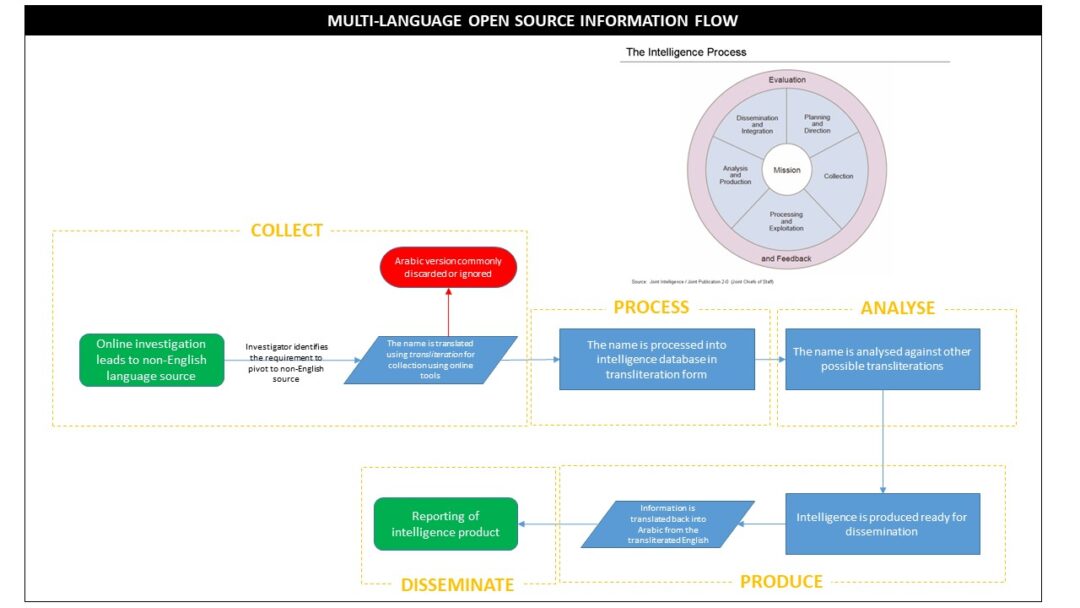
Without validating the input against the output, there is significant potential for cascading errors to occur throughout the intelligence cycle. This starts with the discarding of the native language version of the information, in this case, Arabic. The result is an inability to conduct validation against the native language during the analysis and dissemination phases.
Vignette
Using the flowchart provided in Figure 1, the following example serves to highlight the potential deviation in information accuracy as part of the intelligence cycle when no native language validation is conducted. The name provided is a less-common Arabic name to demonstrate the potential deviations that can occur. Note: the transliteration is not inclusive of all variants. The error rate would grow with more variants included.
- Input variables:
- Information collected online: A person’s first name
- Arabic name collected in raw form:عباس
- Processing variables:
- English transliteration variants (samples): Abbas, Abas, Abaas, Aubaas
- Output variables:
- Arabic versions (samples) that could be translated back out from transliterated ,ابعاس ,اباص ,اباس ,اباس ,ابباس ,ابباص ,عباص ,عباس:
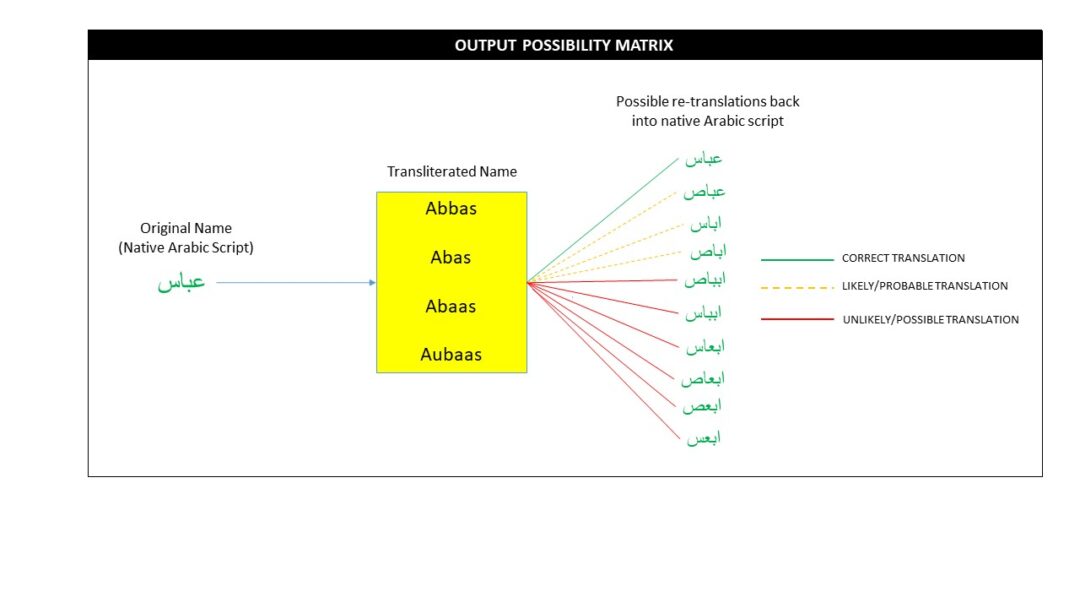
Using the information flow in Figure 2, if the name was fused with other forms of intelligence and a new intelligence product was produced for dissemination (e.g. supporting a warrant), it is highly plausible that when the transliterated name went through re-translation it could become incorrect. This is problematic when prosecuting a target as there is a possibility of mistaken identity or the action itself can become invalid during judicial processing as the name provided with associated evidence may not align correctly to the individual apprehended.
The Validation Loop
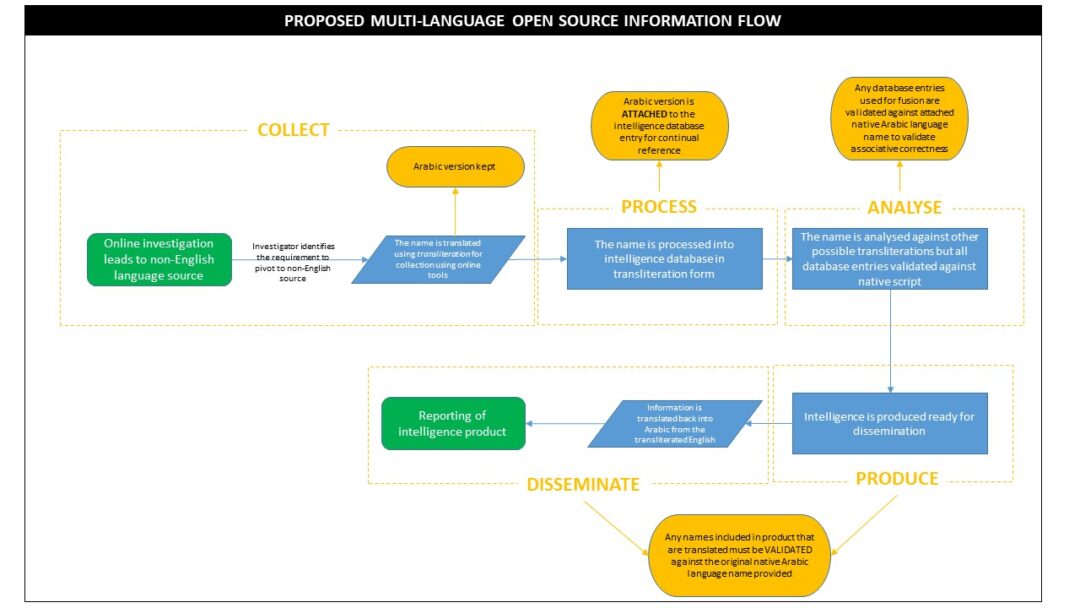
The solution to the problem is both simple and process driven. Linguistic skills are not mandatory but are highly beneficial. Simply an ability to validate transliterated information (primarily names and places) against originating native language content (e.g. Arabic script) throughout the intelligence cycle by conducting visual comparisons of content. Doing so only requires an analyst be able to compare two items of text (the original and the re-translated) to close the validation loop. There is no requirement to know the alphabet of the native language, simply an ability to do rudimentary item comparisons.
Intelligence Cycle Phases. The changes below highlight the key phases where validation must occur to ensure accuracy of associated information:
- During the processing phase the original native language text should be attached to the relevant database entry for review throughout the intelligence cycle.
- During the analysis phase where an analyst must compare all corroborating/supporting intelligence that is used for fusion a continual comparison and validation loop must occur with the original text of the respective database entry. This is to validate that all fused intelligence items align with the correct native language spelling and are therefore accurate and correct when conducting fusion of a name or place.
- During the processing and dissemination phase the product that is being reported as intelligence must be validated against the original text to ensure the information is accurate and aligns with the original information provided.
The below flowchart depicts the process of the proposed continual validation loop:
Conclusion
In open source investigations there will inherently be a pivot point where information sources related to your investigation involve multiple languages. Literal accuracy matters regarding names of individuals and places. When the information originates from a native language source it must be validated throughout the intelligence cycle if transliteration has occured.
Failing to accurately validate native language information could result in mistaken identity, incorrect area identification and hamper prosecution.
Recommendations
The follow recommendations are provided with the intent to enhance the accuracy of multi-language sourced information that is produced into intelligence when conducting online investigations:
- Amend any processes related to the collection, processing, analysis, production and dissemination of intelligence to include the validation when content analysed involves transliterated English and original native language content.
- Establish methods of accountability to the validation process by creating markers or measurements to specify how product has been validated against its originating content when referring to names and places. This will assist if the information is ever required for judicial purposes.
References:
[1] Kenneth Lieberthal, The U.S. Intelligence Community and Foreign Policy – Getting Analysis Right (Washington DC: The Brookings Institution), 22.
[2] “Arabic Language Word Number Comparison with Other Languages”, Sebil Center. http://www.sebilcenter.com/newsdet.html.