OSINT Collection Schema
Evan Davies | Sep 22, 2019 | 5 MIN READ
Updated: May 2, 2023
There is a lot of great information and tools out there that focus on “how” to collect publicly available information and equally a lot of great courses that develop an analytical mindset to derive the real value from open source information and produce actual intelligence. However, there is often a void for newcomers and seasoned OSINT practitioners alike when addressing the following 3 critical questions:
- What should I be collecting? (meaning actual content, not the directed broader intelligence requirements)
- How do I structure & log the information properly?
- How are things related/linked?
There are many ways to tackle these questions and what I discuss throughout this post is simply a method that aim to:
- Help define your collection plan based on operational requirements and;
- Structure what you collect in a way that is repeatable, universal and provide flexibility to ingest into other analytical systems (human or technological) to derive additional meaning and produce intelligence.
In a way the approach described can be used for analysis itself through identifying relationships, but for this post the primary focus is on answering the 3 questions outlined at the top. What to focus collection efforts on, how to structure the collection & input it into a database, and work down the rabbit hole in a meaningful way by understanding how things are linked.
The Approach
When you zoom into the schema you will see a Venn diagram surrounded by entity schemas.
What are we trying to do here?
Essentially we are trying to provide a relationship based diagram (Venn diagram) for how different entities/things can be linked or are related. It can take a little getting used to when exploring the pathways of a Venn diagram but lets look at it closer:
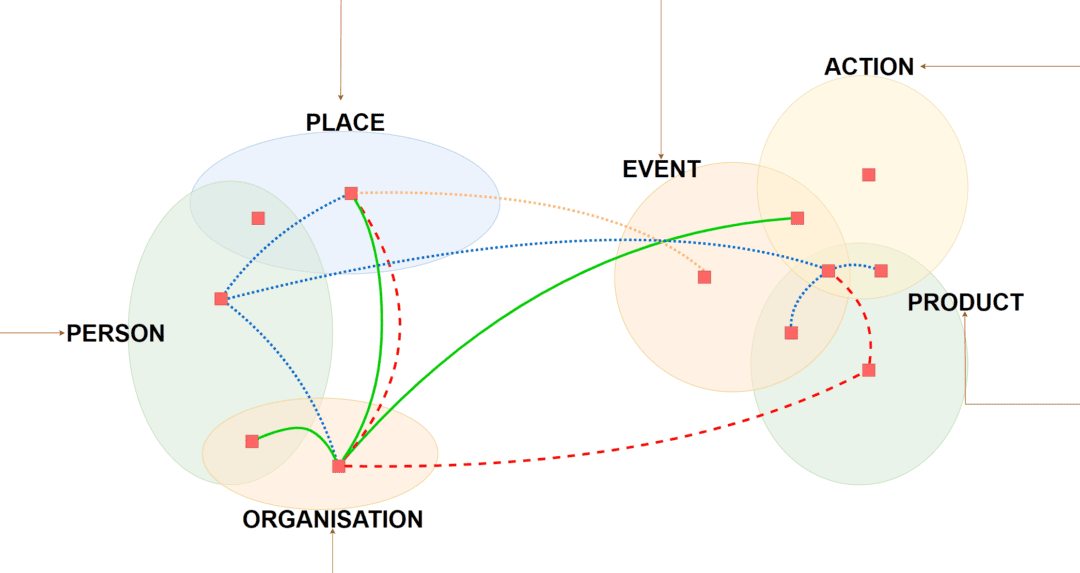
Using a Person entity as a start point for collection you can see how the pathway creates a relationship with all other entities to clearly specify how they may be linked (and how you can report them). Inversley, if you identified an Action entity (e.g. someone attacked something with the event being the attack) you can quickly follow the pathways for how it is overlapped with an Event and can link directly to a Place or Person and through a 2nd/3rd order path it could possibly link to an Organisation.
What about these schema tables?
These schemas (covering People, Places, Organisations, Events, Actions and Products) are derived directly from www.schema.org and are a tabulated way to capture attributes or information related to an entity. You do not need to use every attribute, and often most are blank, but if you build your database with a copy & paste of the schema table you will be setup for success for integration with other systems, or just to have a universal method to collect and report.
What is schema.org?
“Founded by Google, Microsoft, Yahoo and Yandex, Schema.org vocabularies are developed by an open community process, using the [email protected] mailing list and through GitHub.”
This is critically important to creating a universal model for repeatable success and compatibility with most other systems. Given a lot of OSINT collection occurs across Microsoft, Google, Yahoo and Yandex services this should make immediate sense.
You can view the schemas in the main diagram above (which is to represent how the relationship & collection schemas are mutually supportive), but also grab them directly from here:
- People: https://schema.org/Person
- Places: https://schema.org/Place
- Events: https://schema.org/Event
- Organisations: https://schema.org/Organization
- Actions: https://schema.org/Action
- Products: https://schema.org/Product
What should you do with them?
- In simple terms or small scale investigations you could simple use them as a reference to track what is worth collecting and queue onto other things to look for.
- Possibly create your linked diagrams in Maltego, Peliscope or OCCRP visualisation tools ( https://vis.occrp.org/) using the Venn diagram above as a guide or simply configure the entities within each tool using the schemas provided for a more comprehensive approach.
- In more complex terms you can configure your own relational database (MySQL for example) to use for case management or work with developers to use Cloud services to do something similar.
Use-case Scenario
Lets explore this in a use-case scenario.
- Starting with a Person of interest we begin our OSINT collection across Facebook, Instagram, Public record databases, LinkedIn etc etc. We use the Person schema to capture the relevant information about the person and log it in a structured manner.
- Now we look at the Venn diagram and we see that immediately we should be looking to Places & Organisations as related entities and start to collect information on those which are associated with the original person. For example, we identify that the Person visits a cafe routinely, so we collect associated information about the Organisation & the Place using the schema so the information is uniform and directed. We also have the ability to log additional information so don’t think it is strict and all other information should be ignored – it should definitely be captured if it is of relevance.
- In one example we could now be looking for potentially Actions or Events that occurred at one of the Places and finding associated information and possibly expanding the network of people that were present for further investigation. In the same fashion we could simply be looking at Events the person attended and any Actions that occurred there.
As you can see, and I’m sure from many peoples experience, it is a challenging and endless rabbit hole of information. Creating boundaries is key and this comes from clearly defining the intelligence requirements which will direct the collection phase. This post is all about trying to direct effective collection, establish structure to the collection and understand how things are related.
We hope you enjoyed the post, for any feedback or followup questions feel free to contact us at:
Twitter: @osintcombine